castform is the easiest way to train open-weights models on your specific tasks and proprietary data. you define what good looks like: we handle data prep, gpu infra, algorithms, and provide an ide to iterate on and monitor your job.
today, we’re launching castform in open beta.
train a model todaya founder friend showed me his anthropic bill last month. $40k/mo in api costs. every new feature & performance fix they’d added pushed cost up → longer prompts, more tool calls, bigger models, more retries.
meanwhile, there are open-weights models that are 10-20x cheaper. out of the box, their capabilities lag behind closed api models - but trained on your task, they close the gap.
the move everyone says to not make (i.e. training your own model), is actually the correct one. so why isn’t everyone doing it?
because training is mostly plumbing.
my first brush with this was in 2014 - fine-tuning word2vec on biology textbooks to generate quizzes. thought it’d take a weekend. took the whole summer - bad learning rates, silent non-convergence, and gpu wrangling. the important, interesting part - what should this model be good at & how to measure it - took ~2 weeks.
a decade later, it should be easier. with reinforcement learning you can define what good looks like - rubrics, tests, reward heuristics - and watch the model hill-climb the heck out of it.
but the plumbing got worse. you need data in a trainable form. you need to monitor whether it’s getting smarter or just gaming rewards. you need to pick the right algorithmic recipes and pray it converges. you need to wrangle gpus.
most folks who’d love to train a model still never get to the interesting part.
today we’re launching castform, a reinforcement learning training platform for open-weights models that flips the ratio. your job is to figure out what behavior you want and how to measure it. castform handles everything else. the goal’s to make post-training as approachable as prompt engineering.
”everything else” is four things
data
a model’s only as good as the data it gets. for rl post-training, the dataset isn’t a static file → it’s a sandbox the model practices in. it encapsulates the tools the model can call, how model outputs are scored & how data becomes prompts. with castform, a simple BaseEnv lets you specify this for any task.
on top of that, we’ve built support for the two places training data usually comes from:
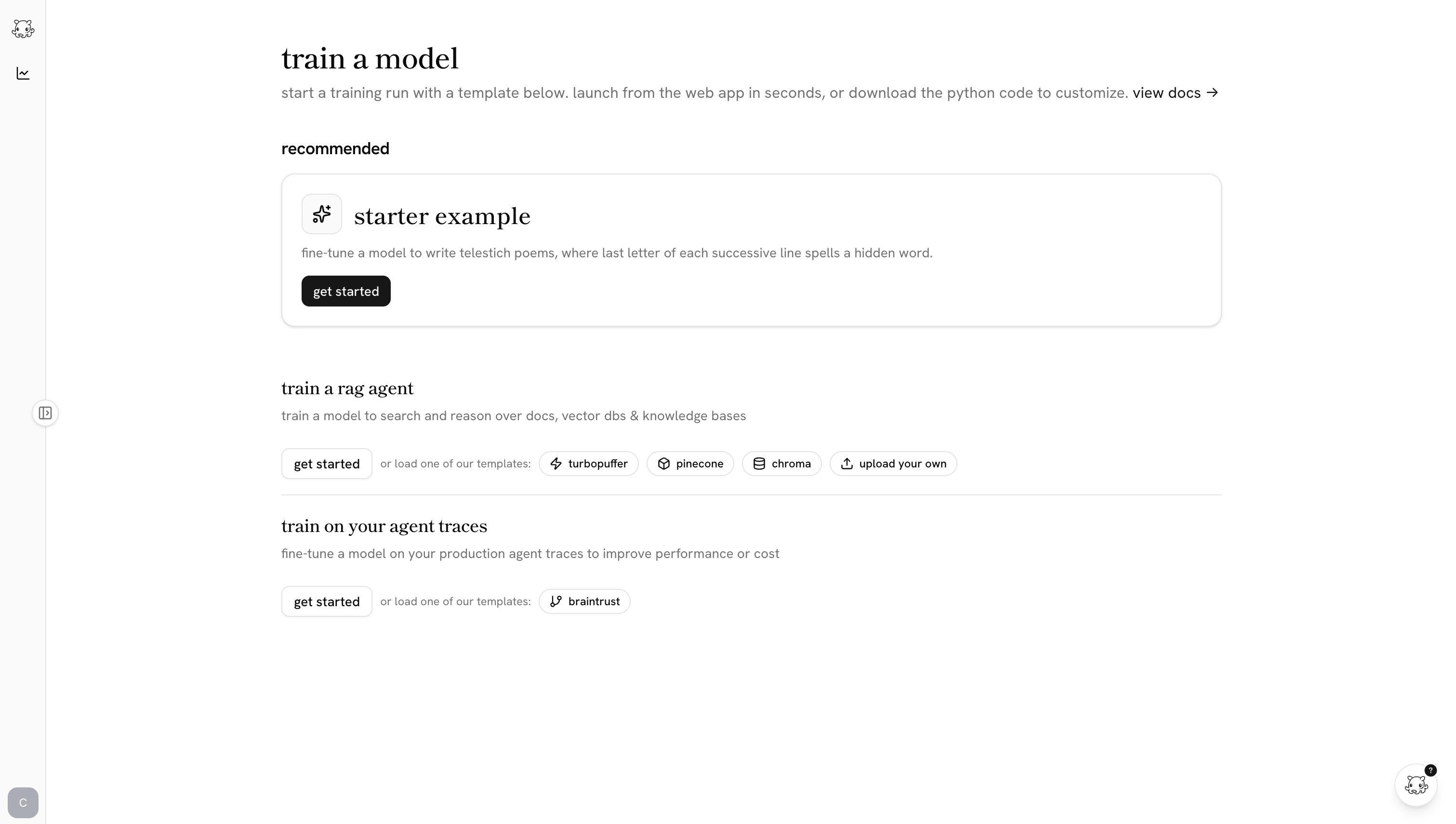
production traces. connect your trace provider and castform will ingest production agent traces - tool calls, model outputs, downstream eval scores - and turn them into training examples. the edge cases your agent hits in prod become training data.
your corpus. point castform at a vector db, document store, or folder of pdfs. we generate hard question-answer pairs grounded in the data, and build a search environment around it.
now you have the inputs. the next question is whether the model is actually learning from it.
the post-training ide
the biggest predictor of whether you ship a good model is how tight your iteration loop is. castform’s post-training ide makes the loop as tight as possible.
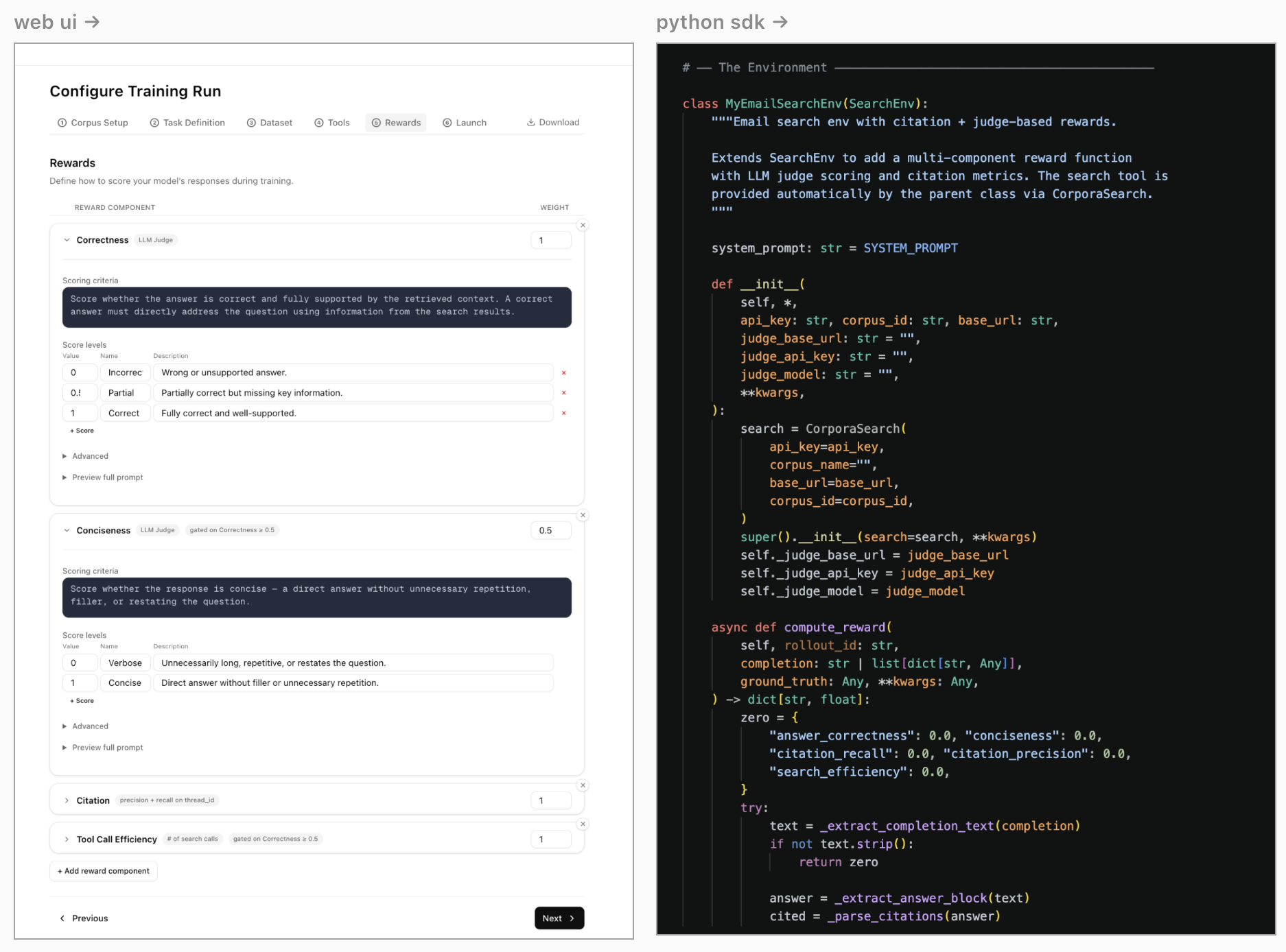
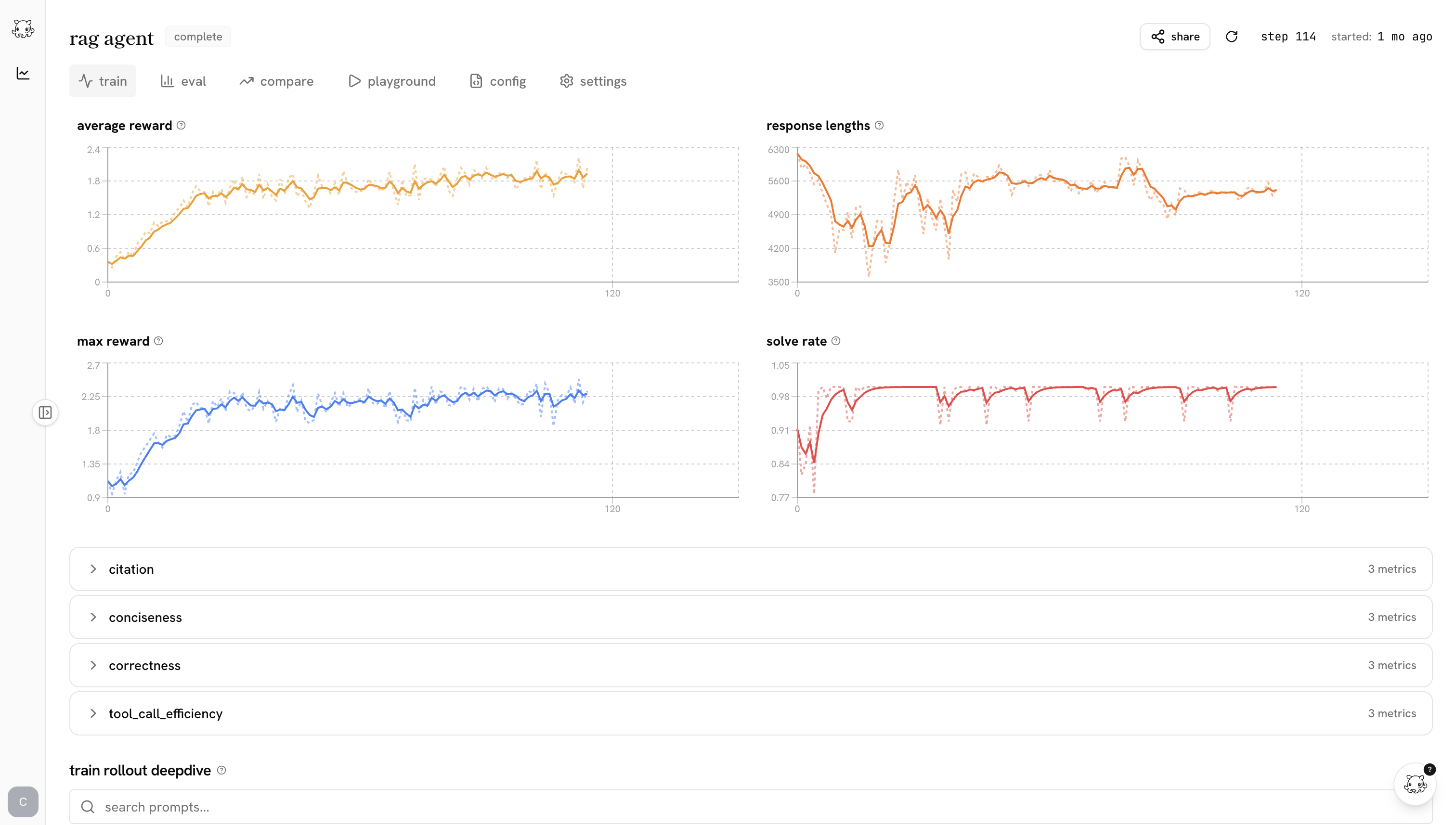
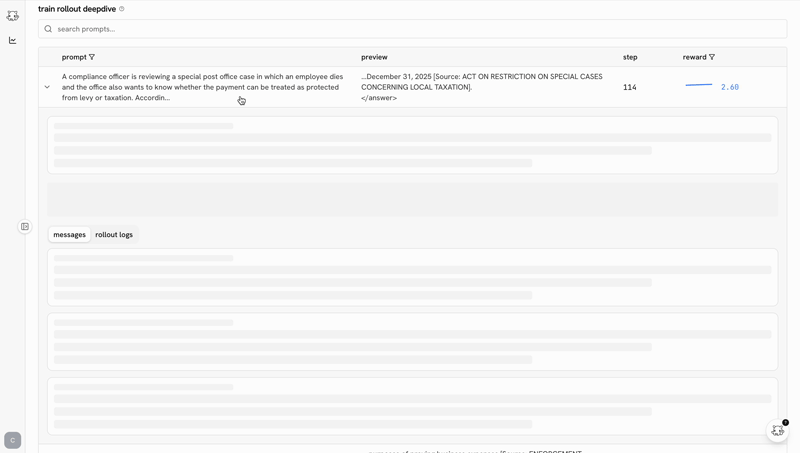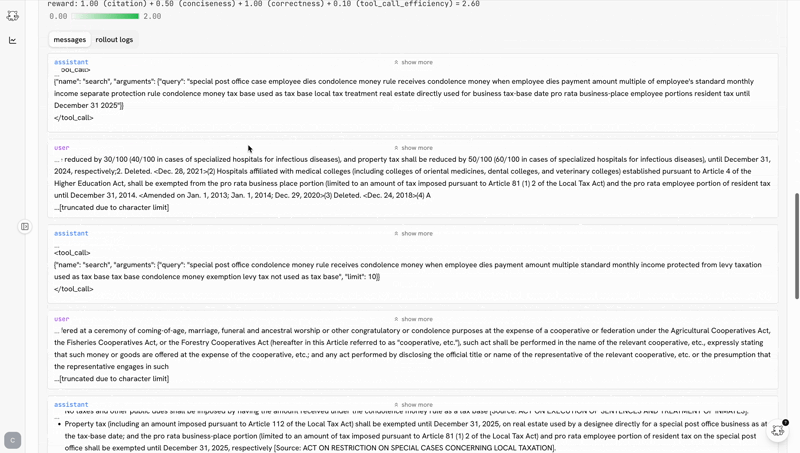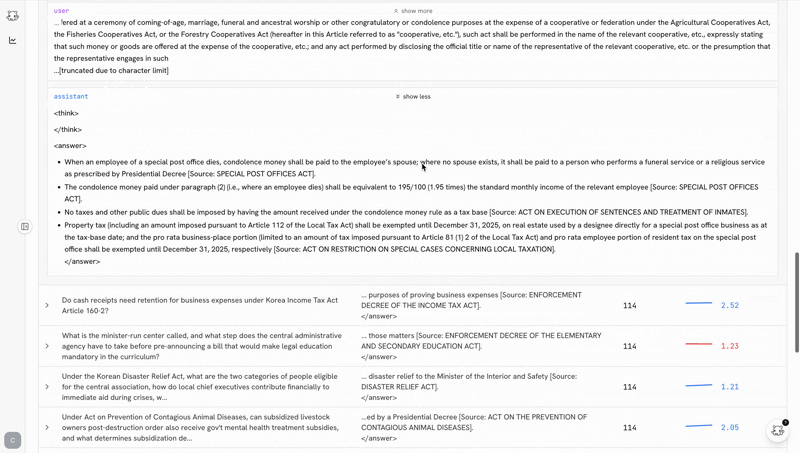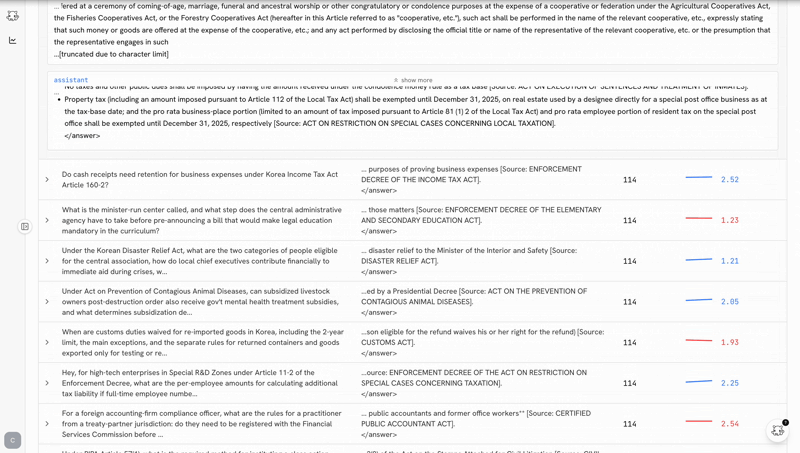
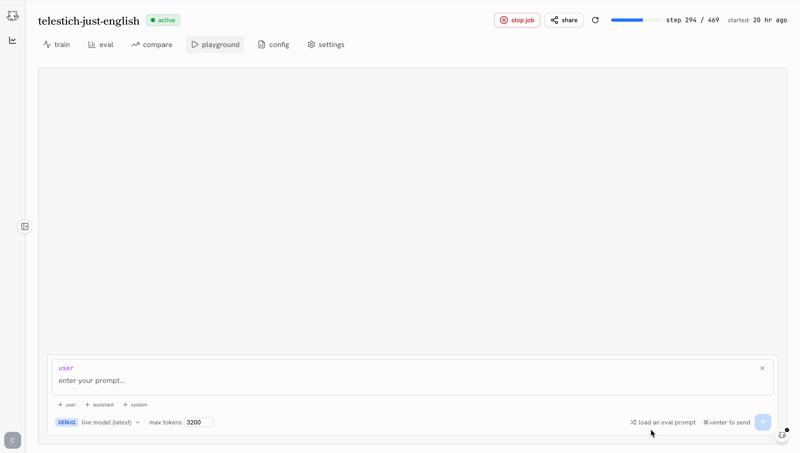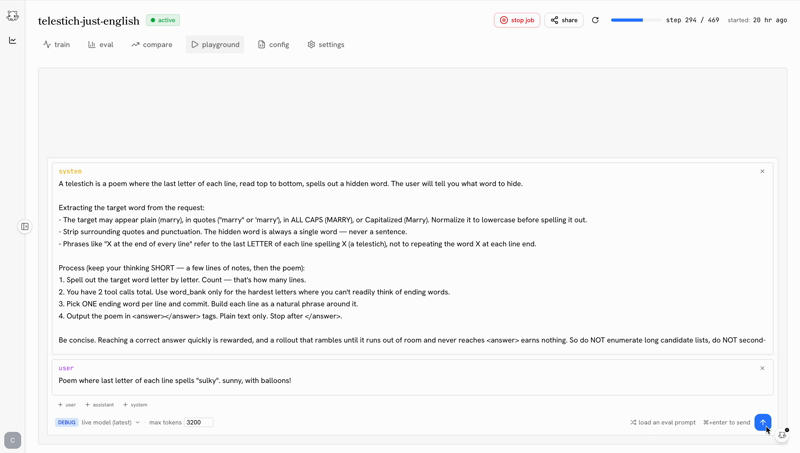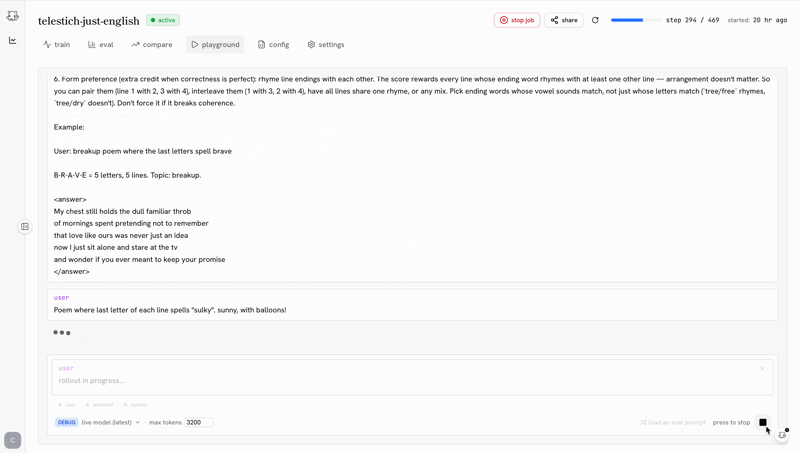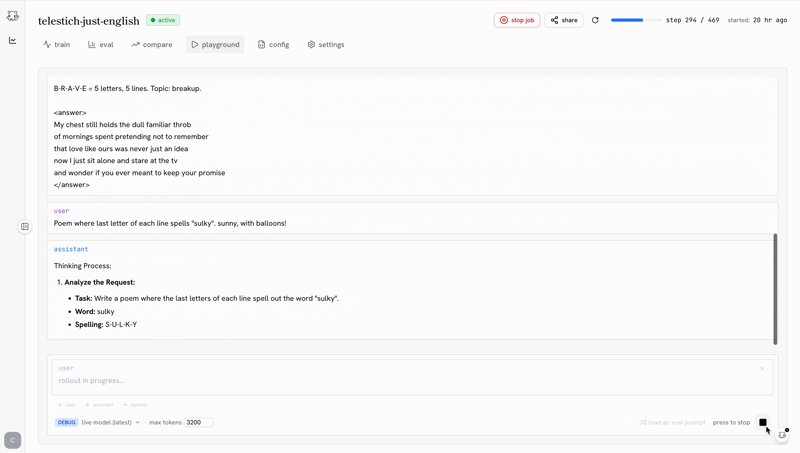
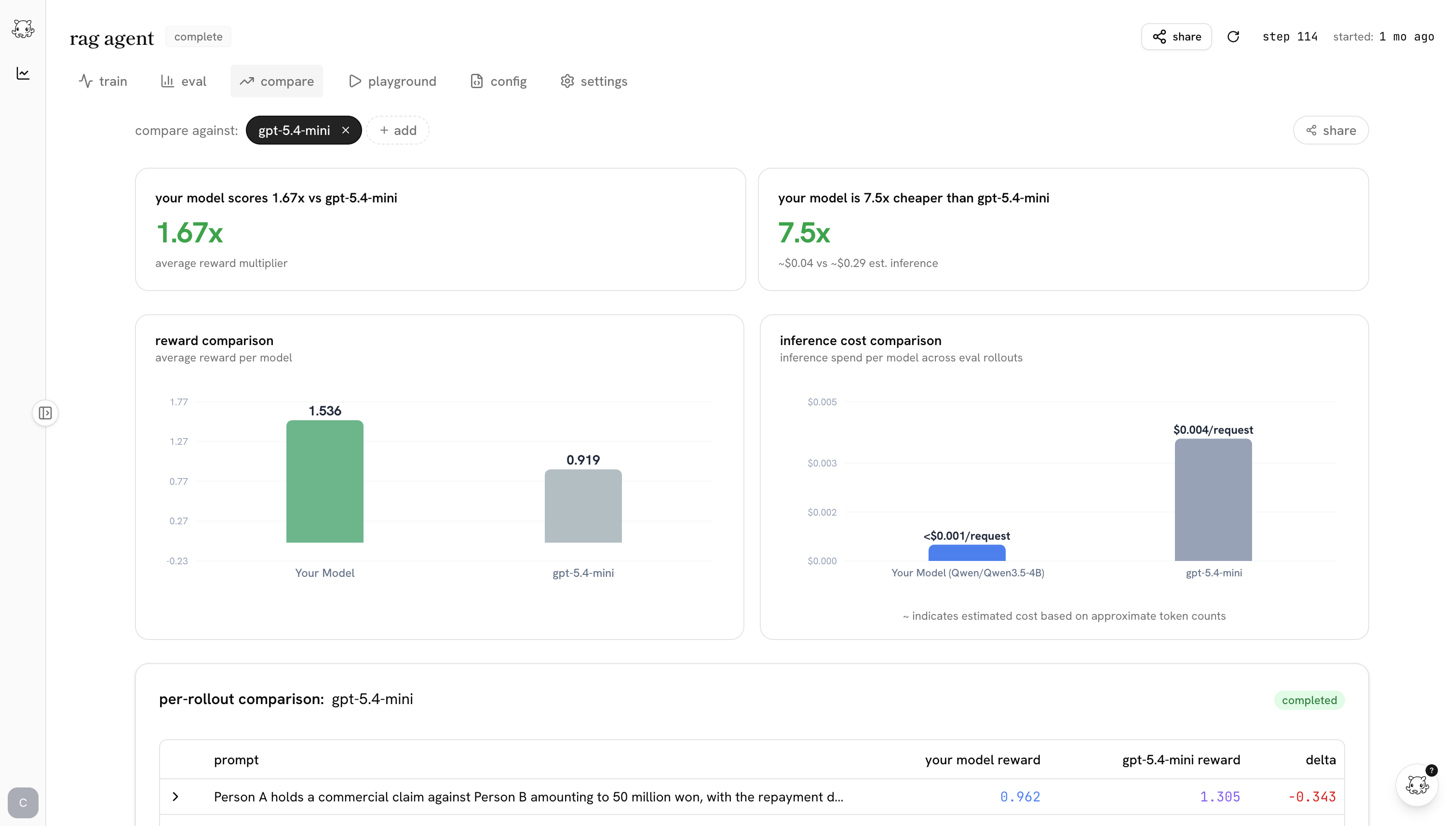
training shouldn’t be a black box you peek into when it crashes. the ide makes the whole run legible while it’s happening.
algorithms
there are a gazillion rl algorithms/variants of grpo. each has quite a few knobs that can silently kill your run when set wrong. we’ve tuned them so your first run produces a useful model instead of a flat/crashing reward curve. advantage normalization, learning rate schedules, group sizes - picked to work out of the box. override any of it when you need to.
infrastructure
even with perfect algorithms, training still needs somewhere to run.
you hit launch and your job is running - right hardware, right cuda version, right distributed setup. no node types to pick, no manual cluster spin-up. we handle gpu provisioning, dependency hell, checkpointing, training-inference mismatch, and the dozen other things that quietly eat weeks of your life.
you hit launch. the rest is our problem.
what we’re betting on
- there will be more than one god. the future won’t be one god model that solves everything. it will be millions of specialized models trained by teams closest to the problem & better at the task than generalists will be. compute is and will remain scarce → specialization is how to get around that.
- model training is a learnable craft. not rocket science, not phd-gated. it’s more like designing a product, that gets better with iteration & taste. we want the tooling to be good so that anyone with taste can get good at it.
- training is never done. model training isn’t one and done. the training pipeline that produces v0.1 should keep running on real prod traces & edge-cases. your model keeps getting better while costs remain flat.
building a cheaper, better model comes down to one thing: defining what it should be good at and how to measure it. castform frees you up to focus on that.
castform’s in early access. if you’ve got an unusual use-case & want a fellow human to think through it with you, reach out at finetune@castform.com — those are the chats we’re most excited about.
train your first model